Note
Go to the end to download the full example code.
Preprocessing with variance threshold, zscore and PCA¶
This example uses the make_regression function to create a simple dataset,
performs a simple regression after the preprocessing of the features
including removal of low variance features, feature normalization for only
two features using zscore and feature reduction using PCA.
We will check the features after each preprocessing step.
# Authors: Shammi More <s.more@fz-juelich.de>
# Leonard Sasse <l.sasse@fz-juelich.de>
# License: AGPL
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.datasets import make_regression
from julearn import run_cross_validation
from julearn.inspect import preprocess
from julearn.pipeline import PipelineCreator
from julearn.utils import configure_logging
Set the logging level to info to see extra information.
configure_logging(level="INFO")
2026-06-02 08:30:24,759 - julearn - INFO - ===== Lib Versions =====
2026-06-02 08:30:24,759 - julearn - INFO - numpy: 2.4.6
2026-06-02 08:30:24,759 - julearn - INFO - scipy: 1.17.1
2026-06-02 08:30:24,759 - julearn - INFO - sklearn: 1.8.0
2026-06-02 08:30:24,759 - julearn - INFO - pandas: 3.0.3
2026-06-02 08:30:24,759 - julearn - INFO - julearn: 0.3.6.dev72
2026-06-02 08:30:24,759 - julearn - INFO - ========================
Create a dataset using sklearn make_regression.
df = pd.DataFrame()
X, y = [f"Feature {x}" for x in range(1, 5)], "y"
df[X], df[y] = make_regression(
n_samples=100, n_features=4, n_informative=3, noise=0.3, random_state=0
)
# We only want to zscore the first two features, so let's get their names.
first_two = X[:2]
# We can define a dictionary, in which the 'key' defines the names of our
# different 'types' of 'X'. The 'value' determine, which features belong to
# this type.
X_types = {"X_to_zscore": first_two}
Let’s look at the summary statistics of the raw features.
print("Summary Statistics of the raw features : \n", df.describe())
Summary Statistics of the raw features :
Feature 1 Feature 2 Feature 3 Feature 4 y
count 100.000000 100.000000 100.000000 100.000000 100.000000
mean -0.111790 0.141618 0.023682 -0.167718 -14.686170
std 0.977322 0.972988 1.087946 0.895011 79.741431
min -2.069985 -2.772593 -2.552990 -2.659172 -204.293317
25% -0.751257 -0.484100 -0.759419 -0.688891 -64.724008
50% -0.206729 0.194442 -0.028152 -0.174160 -16.789944
75% 0.421885 0.724302 0.772156 0.408321 30.392804
max 1.943621 2.256723 2.383145 2.259309 216.221085
We will preprocess all features using variance thresholding.
We will only zscore the first two features, and then perform PCA using all
features. We will zscore the target and then train a random forest model.
Since we use the PipelineCreator object we have to explicitly declare which
X_types each preprocessing step should be applied to. If we do not declare
the type in the add method using the apply_to keyword argument,
the step will default to "continuous" or to another type that can be
declared in the constructor of the PipelineCreator.
To transform the target we could set apply_to="target", which is a special
type, that cannot be user-defined. Please note also that if a step is added
to transform the target, you also have to explicitly add the model that is
to be used in the regression to the PipelineCreator.
# Define model parameters and preprocessing steps first
# The hyperparameters for each step can be added as a keyword argument and
# should be either one parameter or an iterable of multiple parameters for a
# search.
# Setting the threshold for variance to 0.15, number of PCA components to 2
# and number of trees for random forest to 200.
# By setting "apply_to=*", we can apply the preprocessing step to all features.
pipeline_creator = PipelineCreator(problem_type="regression")
pipeline_creator.add("select_variance", apply_to="*", threshold=0.15)
pipeline_creator.add("zscore", apply_to="X_to_zscore")
pipeline_creator.add("pca", apply_to="*", n_components=2)
pipeline_creator.add("rf", apply_to="*", n_estimators=200)
# Because we have already added the model to the pipeline creator, we can
# simply drop in the ``pipeline_creator`` as a model. If we did not add a model
# here, we could add the ``pipeline_creator`` using the keyword argument
# ``preprocess`` and hand over a model separately.
scores, model = run_cross_validation(
X=X,
y=y,
X_types=X_types,
data=df,
model=pipeline_creator,
scoring=["r2", "neg_mean_absolute_error"],
return_estimator="final",
seed=200,
)
# We can use the final estimator to inspect the transformed features at a
# specific step of the pipeline. Since the PCA was the last step added to the
# pipeline, we can simply get the model up to this step by indexing as follows:
X_after_pca = model[:-1].transform(df[X])
print("X after PCA:")
print("=" * 79)
print(X_after_pca)
# We can select pipelines up to earlier steps by indexing previous elements
# in the final estimator. For example, to inspect features after the zscoring
# step:
X_after_zscore = model[:-2].transform(df[X])
print("X after zscore:")
print("=" * 79)
print(X_after_zscore)
# However, to make this less confusing you can also simply use the high-level
# function ``preprocess`` to explicitly refer to a pipeline step by name:
X_after_pca = preprocess(model, X=X, data=df, until="pca")
X_after_zscore = preprocess(model, X=X, data=df, until="zscore")
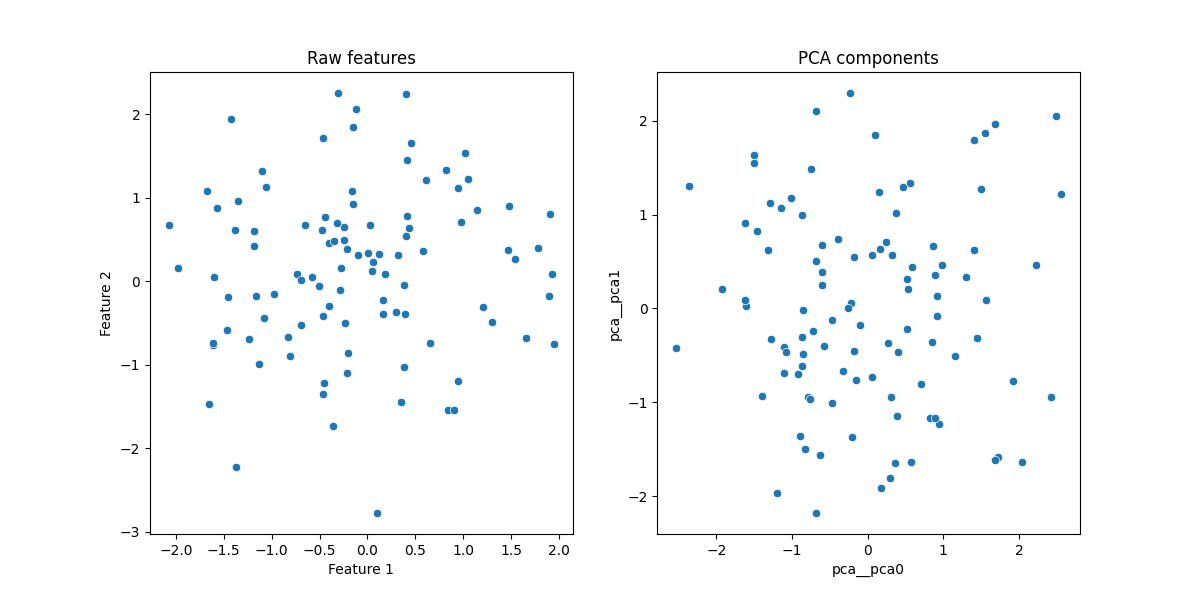
# Let's plot scatter plots for raw features and the PCA components.
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
sns.scatterplot(x=X[0], y=X[1], data=df, ax=axes[0])
axes[0].set_title("Raw features")
sns.scatterplot(x="pca0", y="pca1", data=X_after_pca, ax=axes[1])
axes[1].set_title("PCA components")
2026-06-02 08:30:24,774 - julearn - INFO - Adding step select_variance that applies to ColumnTypes<types={'*'}; pattern=.*>
2026-06-02 08:30:24,775 - julearn - INFO - Setting hyperparameter threshold = 0.15
2026-06-02 08:30:24,775 - julearn - INFO - Step added
2026-06-02 08:30:24,775 - julearn - INFO - Adding step zscore that applies to ColumnTypes<types={'X_to_zscore'}; pattern=(?:__:type:__X_to_zscore)>
2026-06-02 08:30:24,775 - julearn - INFO - Step added
2026-06-02 08:30:24,775 - julearn - INFO - Adding step pca that applies to ColumnTypes<types={'*'}; pattern=.*>
2026-06-02 08:30:24,775 - julearn - INFO - Setting hyperparameter n_components = 2
2026-06-02 08:30:24,776 - julearn - INFO - Step added
2026-06-02 08:30:24,776 - julearn - INFO - Adding step rf that applies to ColumnTypes<types={'*'}; pattern=.*>
2026-06-02 08:30:24,776 - julearn - INFO - Setting hyperparameter n_estimators = 200
2026-06-02 08:30:24,776 - julearn - INFO - Step added
2026-06-02 08:30:24,776 - julearn - INFO - Setting random seed to 200
2026-06-02 08:30:24,776 - julearn - INFO - ==== Input Data ====
2026-06-02 08:30:24,776 - julearn - INFO - Using dataframe as input
2026-06-02 08:30:24,776 - julearn - INFO - Features: ['Feature 1', 'Feature 2', 'Feature 3', 'Feature 4']
2026-06-02 08:30:24,777 - julearn - INFO - Target: y
2026-06-02 08:30:24,777 - julearn - INFO - Expanded features: ['Feature 1', 'Feature 2', 'Feature 3', 'Feature 4']
2026-06-02 08:30:24,777 - julearn - INFO - X_types:{'X_to_zscore': ['Feature 1', 'Feature 2']}
2026-06-02 08:30:24,777 - julearn - WARNING - The following columns are not defined in X_types: ['Feature 3', 'Feature 4']. They will be treated as continuous.
/tmp/tmpe_uj5qr7/julearn/prepare.py:609: RuntimeWarning: The following columns are not defined in X_types: ['Feature 3', 'Feature 4']. They will be treated as continuous.
warn_with_log(
2026-06-02 08:30:24,778 - julearn - INFO - ====================
2026-06-02 08:30:24,779 - julearn - INFO -
2026-06-02 08:30:24,779 - julearn - INFO - = Model Parameters =
2026-06-02 08:30:24,779 - julearn - INFO - ====================
2026-06-02 08:30:24,779 - julearn - INFO -
2026-06-02 08:30:24,779 - julearn - INFO - = Data Information =
2026-06-02 08:30:24,779 - julearn - INFO - Problem type: regression
2026-06-02 08:30:24,780 - julearn - INFO - Number of samples: 100
2026-06-02 08:30:24,780 - julearn - INFO - Number of features: 4
2026-06-02 08:30:24,780 - julearn - INFO - ====================
2026-06-02 08:30:24,780 - julearn - INFO -
2026-06-02 08:30:24,780 - julearn - INFO - Target type: float64
2026-06-02 08:30:24,780 - julearn - INFO - Using outer CV scheme KFold(n_splits=5, random_state=None, shuffle=False) (incl. final model)
X after PCA:
===============================================================================
pca0 pca1
0 -0.078319 2.336101
1 -0.756861 0.596518
2 1.191895 0.451629
3 -0.750820 0.958497
4 0.121426 -1.599419
.. ... ...
95 0.175061 -0.081051
96 -0.586593 0.325382
97 -1.011121 0.024891
98 0.478725 0.788625
99 0.893666 0.435353
[100 rows x 2 columns]
X after zscore:
===============================================================================
Feature 1__:type:__X_to_zscore ... Feature 4__:type:__continuous
0 -2.013728 ... 0.666996
1 -0.364686 ... -0.872214
2 0.118838 ... 1.234740
3 -0.004437 ... -2.091986
4 0.309092 ... 0.776631
.. ... ... ...
95 -0.206189 ... 0.011287
96 -1.099154 ... 0.156690
97 -0.335538 ... -1.218469
98 -0.049139 ... 0.038198
99 0.240085 ... 0.686765
[100 rows x 4 columns]
Text(0.5, 1.0, 'PCA components')
Let’s look at the summary statistics of the zscored features. We see here that the mean of all the features is zero and standard deviation is one.
print(
"Summary Statistics of the zscored features : \n",
X_after_zscore.describe(),
)
Summary Statistics of the zscored features :
Feature 1 Feature 2 Feature 3 Feature 4
count 1.000000e+02 1.000000e+02 1.000000e+02 1.000000e+02
mean -5.689893e-17 1.387779e-17 4.440892e-18 3.330669e-18
std 1.005038e+00 1.005038e+00 1.005038e+00 1.005038e+00
min -2.013728e+00 -3.010202e+00 -2.380315e+00 -2.797736e+00
25% -6.576015e-01 -6.463286e-01 -7.234239e-01 -5.852417e-01
50% -9.763131e-02 5.456486e-02 -4.788377e-02 -7.233997e-03
75% 5.488094e-01 6.018781e-01 6.914360e-01 6.468533e-01
max 2.113700e+00 2.184776e+00 2.179658e+00 2.725389e+00
Total running time of the script: (0 minutes 1.345 seconds)