Note
This page is a reference documentation. It only explains the function signature, and not how to use it. Please refer to the What you really need to know section for the big picture.
julearn.run_cross_validation¶
- julearn.run_cross_validation(X, y, model, data, X_types=None, problem_type=None, preprocess=None, return_estimator=None, return_inspector=False, return_train_score=False, cv=None, groups=None, scoring=None, pos_labels=None, model_params=None, search_params=None, seed=None, n_jobs=None, verbose=0)¶
Run cross validation and score.
- Parameters:
model (
str|PipelineCreator|BaseEstimator|list[PipelineCreator]) – If string, it will use one of the available models.data (
DataFrame) – DataFrame with the data. See Data for details.X_types (
dict|None, default:None) – A dictionary containing keys with column type as a str and the columns of this column type as a list of str.problem_type – The kind of problem to model.
- Returns:
scores (pd.DataFrame) – The resulting scores (one column for each score specified). Additionally, a ‘fit_time’ column will be added. And, if
return_estimator='all'orreturn_estimator='cv', an ‘estimator’ columns with the corresponding estimators fitted for each CV split.final_estimator (object) – The final estimator, fitted on all the data (only if
return_estimator='all'orreturn_estimator='final')inspector (Inspector | None) – The inspector object (only if
return_inspector=True)
Examples using julearn.run_cross_validation¶



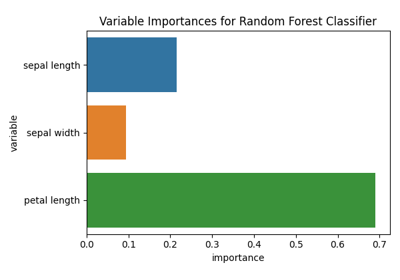
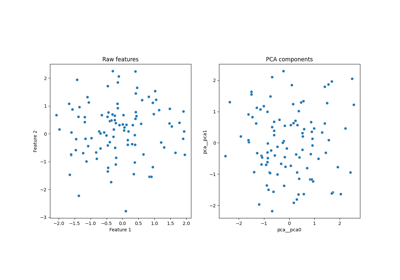
Preprocessing with variance threshold, zscore and PCA


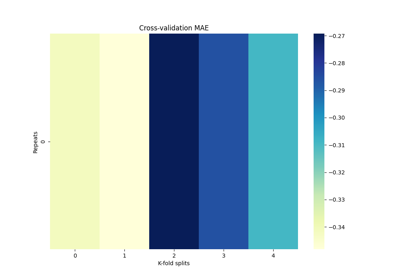





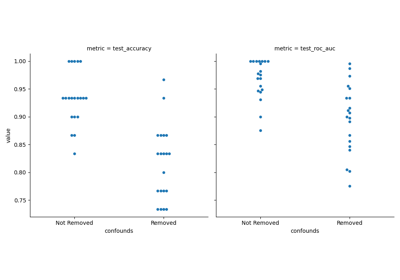



/auto_examples/99_docs/run_cbpm_docs

/auto_examples/99_docs/run_confound_removal_docs

/auto_examples/99_docs/run_hyperparameters_docs

/auto_examples/99_docs/run_model_comparison_docs

/auto_examples/99_docs/run_model_evaluation_docs

/auto_examples/99_docs/run_model_inspection_docs

/auto_examples/99_docs/run_pipeline_docs

/auto_examples/99_docs/run_stacked_models_docs
/auto_examples/99_docs/run_target_transformer_docs