Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the What you really need to know section for the big picture.
julearn.PipelineCreator¶
- class julearn.PipelineCreator(problem_type, apply_to='continuous')¶
PipelineCreator class.
This class is used to create pipelines. As the creation of a pipeline is a bit more complicated than just adding steps to a pipeline, this helper class is provided so the user can easily create complex
sklearn.pipeline.Pipelineobjects.- Parameters:
problem_type (
str) – {“classification”, “regression”, “transformer”}: The problem type for which the pipeline should be created.apply_to (
list[str] |set[str] |str| ColumnTypes, default:'continuous') – ColumnTypesLike, optional: To what should the transformers be applied to if not specified in the add method (default is continuous).
- __init__(problem_type, apply_to='continuous')¶
- add(step, name=None, apply_to=None, row_select_col_type=None, row_select_vals=None, **params)¶
Add a step to the PipelineCreator.
- Parameters:
step (
EstimatorLikeFit1|EstimatorLikeFit2|EstimatorLikeFity|str|TargetPipelineCreator) – The step that should be added. This can be an available_transformer or available_model as a str or a sklearn compatible transformer or model.name (
str|None, default:None) – The name of the step. If None, the name will be obtained from the step (default is None).apply_to (
list[str] |set[str] |str| ColumnTypes |None, default:None) – ColumnTypesLike, optional: To what should the transformer or model be applied to. This can be a str representing a column type or a list of such str (defaults to the PipelineCreator.apply_to attribute).row_select_col_type (
list[str] |set[str] |str| ColumnTypes |None, default:None) – The column types needed to select rows (default is None)row_select_vals (
str|int|list|bool|None, default:None) – The value(s) which should be selected in the row_select_col_type to select the rows used for training (default is None)**params (
Any) – Parameters for the step. This will mostly include hyperparameters or any other parameter for initialization. If you provide multiple options for hyperparameters then this will lead to a pipeline with a search.
- Returns:
The PipelineCreator with the added step as its last step.
- Raises:
ValueError – If the step is not a valid step, if the problem_type is specified in the params or if the step is a TargetPipelineCreator and the apply_to is not “target”.
- has_model()¶
Whether the PipelineCreator has a model.
- copy()¶
Create a copy of the PipelineCreator.
- Returns:
The copy of the PipelineCreator
- classmethod from_list(transformers, model_params, problem_type, apply_to='continuous')¶
Create a PipelineCreator from a list of transformers and parameters.
- Parameters:
transformers (
str|list) – The transformers that should be added to the PipelineCreator. This can be a str or a list of str.model_params (
dict) – The parameters for the model and the transformers. This should be a dict with the keys being the name of the transformer or the model and the values being a dict with the parameters for that transformer or model.problem_type (
str) – The problem_type for which the piepline should be created.apply_to (
list[str] |set[str] |str| ColumnTypes, default:'continuous') – To what should the transformers be applied to if not specified in the add method (default is continuous).
- Returns:
The PipelineCreator with the steps added
- split()¶
Split the PipelineCreator into multiple PipelineCreators.
If the PipelineCreator has at least two steps with the same name, this is considered a split point for hyperparameter tuning. This function will split the PipelineCreator into multiple PipelineCreators, one for each split point, recursively. Thus, creating as many PipelineCreators as needed to tune all the hyperparameters configurations.
- Returns:
A list of PipelineCreators, each one without repeated step names.
- to_pipeline(X_types=None, search_params=None)¶
Create a pipeline from the PipelineCreator.
Examples using julearn.PipelineCreator¶
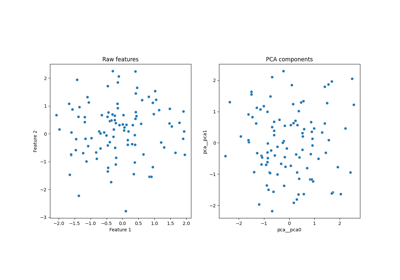
Preprocessing with variance threshold, zscore and PCA


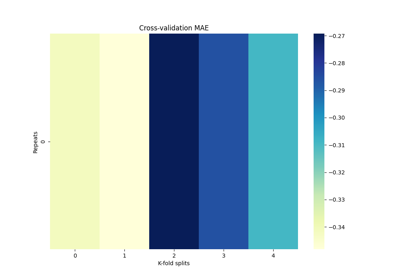





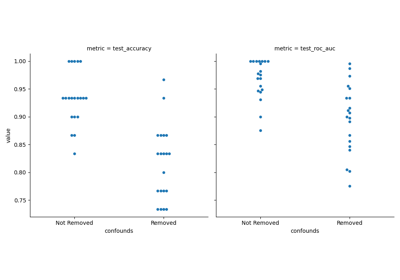


/auto_examples/99_docs/run_cbpm_docs

/auto_examples/99_docs/run_confound_removal_docs

/auto_examples/99_docs/run_hyperparameters_docs

/auto_examples/99_docs/run_model_comparison_docs

/auto_examples/99_docs/run_model_evaluation_docs

/auto_examples/99_docs/run_model_inspection_docs

/auto_examples/99_docs/run_pipeline_docs

/auto_examples/99_docs/run_stacked_models_docs
/auto_examples/99_docs/run_target_transformer_docs