3.1. The Junifer Pipeline#
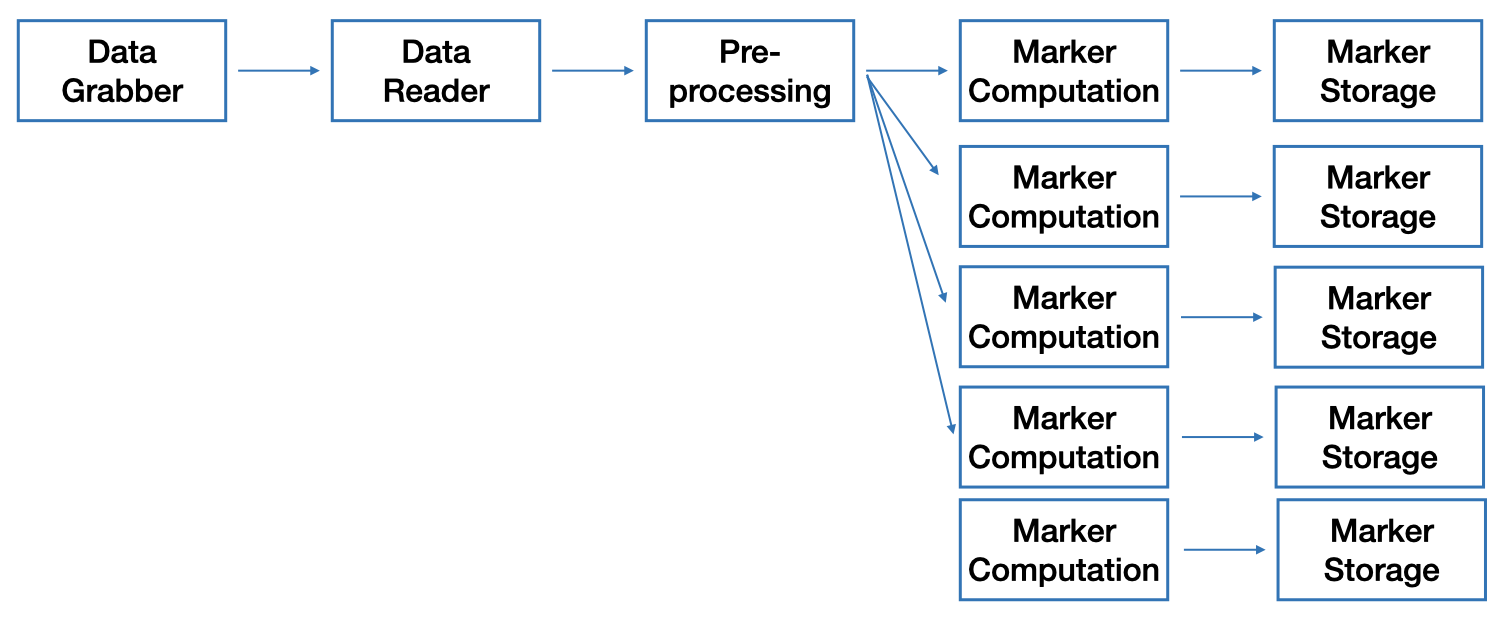
The junifer pipeline is the main execution path of junifer. It consists of five steps:
Data Grabber: Interpret the dataset and provide a list of files.
Data Reader: Read the files.
Pre-processing: Prepare the images for marker computation.
Marker Computation: Compute the marker.
Storage: Store the marker values.
The element that is passed accross the pipeline is called the Data Object.
The following is a graphical representation of the pipeline:

However, it is usually the case that several markers are computed for the same data. Thus, the markers step of the pipeline is defined as a list of markers. The following is a graphical representation of the pipeline execution on multiple markers:
Note
To avoid keeping in memory all of the computed marker, the storage step is called after each marker computation, releasing the memory used to compute each marker.