Note
Go to the end to download the full example code
Confound Removal (model comparison)#
This example uses the ‘iris’ dataset, performs simple binary classification with and without confound removal using a Random Forest classifier.
# Authors: Shammi More <s.more@fz-juelich.de>
# Federico Raimondo <f.raimondo@fz-juelich.de>
# Leonard Sasse <l.sasse@fz-juelich.de>
# License: AGPL
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from seaborn import load_dataset
from julearn import run_cross_validation
from julearn.model_selection import StratifiedBootstrap
from julearn.pipeline import PipelineCreator
from julearn.utils import configure_logging
Set the logging level to info to see extra information
configure_logging(level="INFO")
2026-05-29 20:46:24,294 - julearn - INFO - ===== Lib Versions =====
2026-05-29 20:46:24,294 - julearn - INFO - numpy: 1.25.2
2026-05-29 20:46:24,294 - julearn - INFO - scipy: 1.16.3
2026-05-29 20:46:24,294 - julearn - INFO - sklearn: 1.3.0
2026-05-29 20:46:24,294 - julearn - INFO - pandas: 2.0.3
2026-05-29 20:46:24,294 - julearn - INFO - julearn: 0.3.1.dev0
2026-05-29 20:46:24,294 - julearn - INFO - ========================
Load the iris data from seaborn
df_iris = load_dataset("iris")
The dataset has three kind of species. We will keep two to perform a binary classification.
As features, we will use the sepal length, width and petal length and use petal width as confound.
Doing hypothesis testing in ML is not that simple. If we were to use classical frequentist statistics, we have the problem that using cross validation, the samples are not independent and the population (train + test) is always the same.
If we want to compare two models, an alternative is to contrast, for each fold, the performance gap between the models. If we combine that approach with bootstrapping, we can then compare the confidence intervals of the difference. If the 95% CI is above 0 (or below), we can claim that the models are different with p < 0.05.
Lets use a bootstrap CV. In the interest of time we do 20 iterations, change the number of bootstrap iterations to at least 2000 for a valid test.
n_bootstrap = 20
n_elements = len(df_iris)
cv = StratifiedBootstrap(n_splits=n_bootstrap, test_size=0.3, random_state=42)
First, we will train a model without performing confound removal on features Note: confounds by default
2026-05-29 20:46:24,299 - julearn - INFO - Setting random seed to 200
2026-05-29 20:46:24,299 - julearn - INFO - ==== Input Data ====
2026-05-29 20:46:24,300 - julearn - INFO - Using dataframe as input
2026-05-29 20:46:24,300 - julearn - INFO - Features: ['sepal_length', 'sepal_width', 'petal_length']
2026-05-29 20:46:24,300 - julearn - INFO - Target: species
2026-05-29 20:46:24,300 - julearn - INFO - Expanded features: ['sepal_length', 'sepal_width', 'petal_length']
2026-05-29 20:46:24,300 - julearn - INFO - X_types:{}
2026-05-29 20:46:24,300 - julearn - WARNING - The following columns are not defined in X_types: ['sepal_length', 'sepal_width', 'petal_length']. They will be treated as continuous.
/private/var/folders/09/t22x2_p106j7p24khr0jdxrw0000gn/T/tmp4590_ea2/julearn/utils/logging.py:238: RuntimeWarning: The following columns are not defined in X_types: ['sepal_length', 'sepal_width', 'petal_length']. They will be treated as continuous.
warn(msg, category=category)
2026-05-29 20:46:24,301 - julearn - INFO - ====================
2026-05-29 20:46:24,301 - julearn - INFO -
2026-05-29 20:46:24,301 - julearn - INFO - Adding step zscore that applies to ColumnTypes<types={'continuous'}; pattern=(?:__:type:__continuous)>
2026-05-29 20:46:24,302 - julearn - INFO - Step added
2026-05-29 20:46:24,302 - julearn - INFO - Adding step rf that applies to ColumnTypes<types={'continuous'}; pattern=(?:__:type:__continuous)>
2026-05-29 20:46:24,302 - julearn - INFO - Step added
2026-05-29 20:46:24,303 - julearn - INFO - = Model Parameters =
2026-05-29 20:46:24,303 - julearn - INFO - ====================
2026-05-29 20:46:24,303 - julearn - INFO -
2026-05-29 20:46:24,303 - julearn - INFO - = Data Information =
2026-05-29 20:46:24,303 - julearn - INFO - Problem type: classification
2026-05-29 20:46:24,303 - julearn - INFO - Number of samples: 100
2026-05-29 20:46:24,304 - julearn - INFO - Number of features: 3
2026-05-29 20:46:24,304 - julearn - INFO - ====================
2026-05-29 20:46:24,304 - julearn - INFO -
2026-05-29 20:46:24,304 - julearn - INFO - Number of classes: 2
2026-05-29 20:46:24,304 - julearn - INFO - Target type: object
2026-05-29 20:46:24,305 - julearn - INFO - Class distributions: species
versicolor 50
virginica 50
Name: count, dtype: int64
2026-05-29 20:46:24,305 - julearn - INFO - Using outer CV scheme StratifiedBootstrap(n_splits=20, random_state=42, test_size=0.3,
train_size=None)
2026-05-29 20:46:24,306 - julearn - INFO - Binary classification problem detected.
Next, we train a model after performing confound removal on the features Note: we initialize the CV again to use the same folds as before
cv = StratifiedBootstrap(n_splits=n_bootstrap, test_size=0.3, random_state=42)
# In order to tell 'run_cross_validation' which columns are confounds,
# and which columns are features, we have to define the X_types:
X_types = {"features": X, "confound": confounds}
We can now define a pipeline creator and add a confound removal step. The pipeline creator should apply all the steps, by default, to the features type.
The first step will zscore both features and confounds.
The second step will remove the confounds (type “confound”) from the “features”.
Finally, a random forest will be trained. Given the default apply_to in the pipeline creator, the random forest will only be trained using “features”.
creator = PipelineCreator(problem_type="classification", apply_to="features")
creator.add("zscore", apply_to=["features", "confound"])
creator.add("confound_removal", apply_to="features", confounds="confound")
creator.add("rf")
scores_cr = run_cross_validation(
X=X + confounds,
y=y,
data=df_iris,
model=creator,
cv=cv,
X_types=X_types,
scoring=["accuracy", "roc_auc"],
return_estimator="cv",
seed=200,
)
2026-05-29 20:46:27,841 - julearn - INFO - Adding step zscore that applies to ColumnTypes<types={'confound', 'features'}; pattern=(?:__:type:__confound|__:type:__features)>
2026-05-29 20:46:27,842 - julearn - INFO - Step added
2026-05-29 20:46:27,842 - julearn - INFO - Adding step confound_removal that applies to ColumnTypes<types={'features'}; pattern=(?:__:type:__features)>
2026-05-29 20:46:27,842 - julearn - INFO - Setting hyperparameter confounds = confound
2026-05-29 20:46:27,843 - julearn - INFO - Step added
2026-05-29 20:46:27,843 - julearn - INFO - Adding step rf that applies to ColumnTypes<types={'features'}; pattern=(?:__:type:__features)>
2026-05-29 20:46:27,843 - julearn - INFO - Step added
2026-05-29 20:46:27,843 - julearn - INFO - Setting random seed to 200
2026-05-29 20:46:27,843 - julearn - INFO - ==== Input Data ====
2026-05-29 20:46:27,843 - julearn - INFO - Using dataframe as input
2026-05-29 20:46:27,843 - julearn - INFO - Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
2026-05-29 20:46:27,843 - julearn - INFO - Target: species
2026-05-29 20:46:27,844 - julearn - INFO - Expanded features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
2026-05-29 20:46:27,844 - julearn - INFO - X_types:{'features': ['sepal_length', 'sepal_width', 'petal_length'], 'confound': ['petal_width']}
2026-05-29 20:46:27,845 - julearn - INFO - ====================
2026-05-29 20:46:27,845 - julearn - INFO -
2026-05-29 20:46:27,847 - julearn - INFO - = Model Parameters =
2026-05-29 20:46:27,847 - julearn - INFO - ====================
2026-05-29 20:46:27,847 - julearn - INFO -
2026-05-29 20:46:27,847 - julearn - INFO - = Data Information =
2026-05-29 20:46:27,847 - julearn - INFO - Problem type: classification
2026-05-29 20:46:27,848 - julearn - INFO - Number of samples: 100
2026-05-29 20:46:27,848 - julearn - INFO - Number of features: 4
2026-05-29 20:46:27,848 - julearn - INFO - ====================
2026-05-29 20:46:27,848 - julearn - INFO -
2026-05-29 20:46:27,848 - julearn - INFO - Number of classes: 2
2026-05-29 20:46:27,848 - julearn - INFO - Target type: object
2026-05-29 20:46:27,849 - julearn - INFO - Class distributions: species
versicolor 50
virginica 50
Name: count, dtype: int64
2026-05-29 20:46:27,849 - julearn - INFO - Using outer CV scheme StratifiedBootstrap(n_splits=20, random_state=42, test_size=0.3,
train_size=None)
2026-05-29 20:46:27,849 - julearn - INFO - Binary classification problem detected.
Now we can compare the accuracies. We can combine the two outputs as pandas dataframes
scores_ncr["confounds"] = "Not Removed"
scores_cr["confounds"] = "Removed"
Now we convert the metrics to a column for easier seaborn plotting (convert to long format)
index = ["fold", "confounds"]
scorings = ["test_accuracy", "test_roc_auc"]
df_ncr_metrics = scores_ncr.set_index(index)[scorings].stack()
df_ncr_metrics.index.names = ["fold", "confounds", "metric"]
df_ncr_metrics.name = "value"
df_cr_metrics = scores_cr.set_index(index)[scorings].stack()
df_cr_metrics.index.names = ["fold", "confounds", "metric"]
df_cr_metrics.name = "value"
df_metrics = pd.concat((df_ncr_metrics, df_cr_metrics))
df_metrics = df_metrics.reset_index()
# print(df_metrics.head())
And finally plot the results
sns.catplot(
x="confounds", y="value", col="metric", data=df_metrics, kind="swarm"
)
plt.tight_layout()
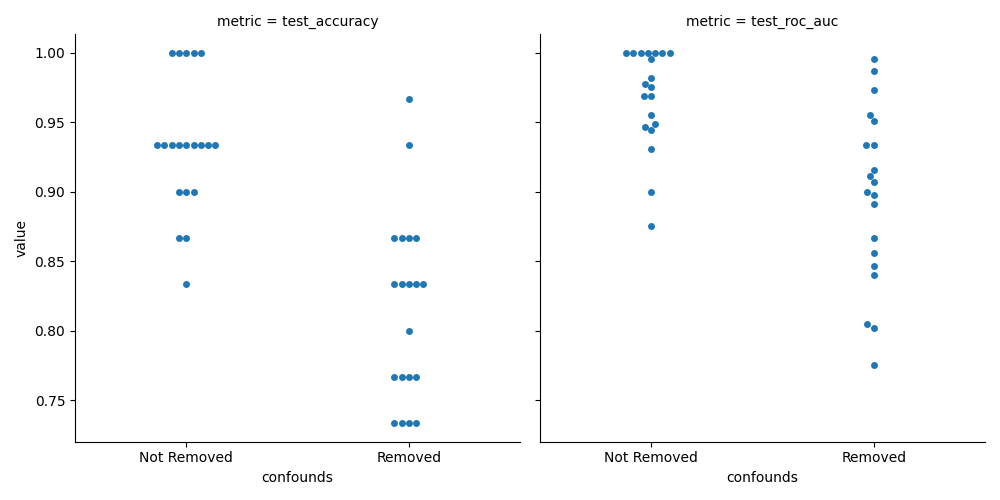
While this plot allows us to see the mean performance values and compare them, these samples are paired. In order to see if there is a systematic difference, we need to check the distribution of differeces between the the models.
First we remove the column “confounds” from the index and make the difference between the metrics
df_cr_metrics = df_cr_metrics.reset_index().set_index(["fold", "metric"])
df_ncr_metrics = df_ncr_metrics.reset_index().set_index(["fold", "metric"])
df_diff_metrics = df_ncr_metrics["value"] - df_cr_metrics["value"]
df_diff_metrics = df_diff_metrics.reset_index()
Now we can finally plot the difference, setting the whiskers of the box plot at 2.5 and 97.5 to see the 95% CI.
sns.boxplot(
x="metric", y="value", data=df_diff_metrics.reset_index(), whis=[2.5, 97.5]
)
plt.axhline(0, color="k", ls=":")
plt.tight_layout()
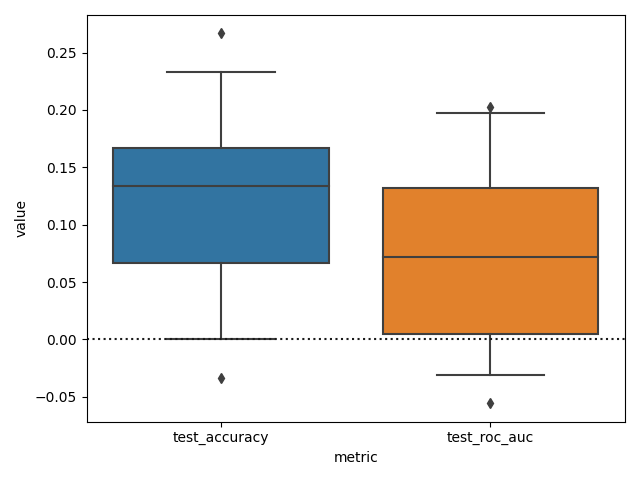
We can see that while it seems that the accuracy and ROC AUC scores are higher when confounds are not removed. We can not really claim (using this test), that the models are different in terms of these metrics.
Maybe the percentiles will be more accuracy with the proper amount of bootstrap iterations?
But the main point of confound removal is for interpretability. Lets see if there is a change in the feature importances.
First, we need to collect the feature importances for each model, for each fold.
ncr_fi = []
for i_fold, estimator in enumerate(scores_ncr["estimator"]):
this_importances = pd.DataFrame(
{
"feature": [x.replace("_", " ") for x in X],
"importance": estimator["rf"].feature_importances_,
"confounds": "Not Removed",
"fold": i_fold,
}
)
ncr_fi.append(this_importances)
ncr_fi = pd.concat(ncr_fi)
cr_fi = []
for i_fold, estimator in enumerate(scores_cr["estimator"]):
this_importances = pd.DataFrame(
{
"feature": [x.replace("_", " ") for x in X],
"importance": estimator["rf"].model.feature_importances_,
"confounds": "Removed",
"fold": i_fold,
}
)
cr_fi.append(this_importances)
cr_fi = pd.concat(cr_fi)
feature_importance = pd.concat([cr_fi, ncr_fi])
We can now plot the importances
sns.catplot(
x="feature",
y="importance",
hue="confounds",
dodge=True,
data=feature_importance,
kind="swarm",
s=3,
)
plt.tight_layout()
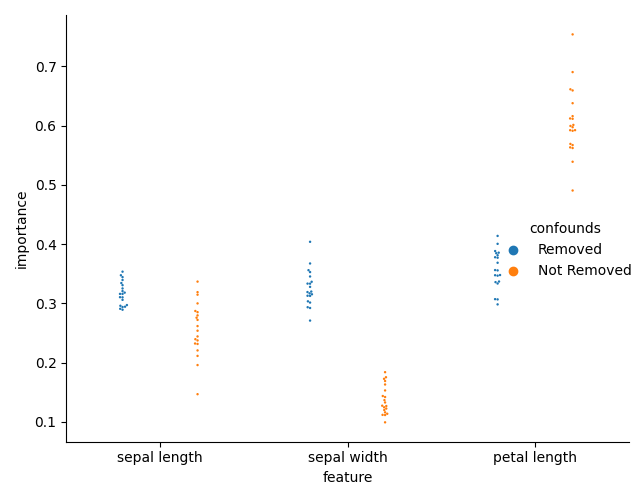
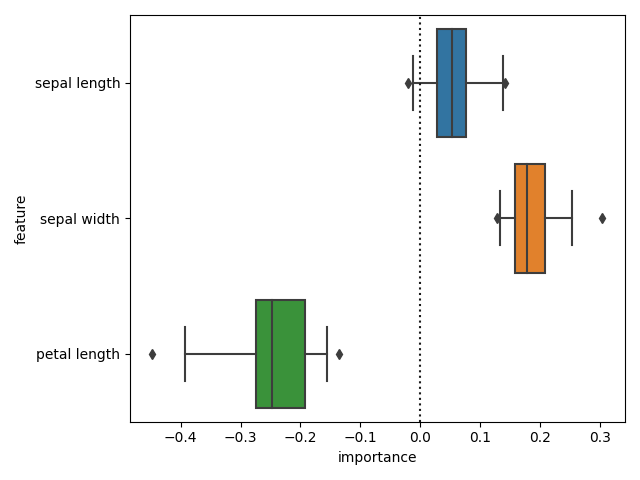
And check the differences in importances. We can now see that there is a difference in importances.
diff_fi = (
cr_fi.set_index(["feature", "fold"])["importance"]
- ncr_fi.set_index(["feature", "fold"])["importance"]
)
sns.boxplot(
x="importance", y="feature", data=diff_fi.reset_index(), whis=[2.5, 97.5]
)
plt.axvline(0, color="k", ls=":")
plt.tight_layout()
Total running time of the script: ( 0 minutes 9.670 seconds)